
object detection에 대해서 알아보자 - STEP 1
업데이트:
카테고리: object detection, 딥러닝
나는 object detection에 대해 잘 안다고 생각했는데, 생각보다 많이 모르는 것 같습니다. 그래서 인터넷 검색을 해봤더니, 시작부터 끝까지 좋은 정리 글이 있는거 같아서 읽고 내용을 정리해보려고 합니다..
object detection에 대해서
 |
|---|
| 그림 1 |
흔히 우리가 분류기를 적용한다고 하면, 그림 1의 왼쪽처럼 이미지 한장에 물체가 하나 있는 것만을 생각하기 쉽습니다. 그래서 이미지 한장 안에 있는 물체가 무엇인가?? 에 대한 질문에 답하기 위해서 분류기를 사용하여 결과를 내죠.
그러나 실제로는 그림 2의 오른쪽처럼 이미지 안에 많은 object들이 있을 수 있습니다. 이들을 각각 분류해내고 위치를 파악하는 기술을 object detection이라고 이야기할 수 있습니다. {정의를 얘기하기보단 이런 기술이다라고 얘기하고 싶습니다.}
object detection의 핵심 단계는 아래와 같습니다.
- 입력 이미지를 모델에 넣는다.
- 3개의 결과를 주로 확인한다.
- bbox
- class label
- probability/confidence score
분명 class lael은 우리가 흔히 아는 분류기를 통해 결과를 내는 느낌인거 같은데.. bbox와 probability/confidence score는 무엇일까요? 이것들을 알려면, 특별한 네트워크 구조가 필요합니다.
Class label을 어떻게 설정할까?
보통 object detection이라고 하면 가장 유명한 R-CNN, YOLO 등을 떠올리곤 합니다. 우리는 CNN 분류기를 object detector로 가져가야되는데, 이 과정을 위해서 전통적인 computer vision 알고리즘을 알아야한다. 요즘엔 computer vision을 기반으로한 전통적인 방법으로 이미지를 분류하진 않지만, 이런 고전 기법들이 딥러닝과 미래 기술들을 더욱 발전하는 것이므로 알아봅시다!
링크에선 object detector로 쓰이는 가장 최신의 computer vision 기술을 HOG + Linear SVM 이라고 합니다. 딥러닝을 이용한 이미지 분류기를 object detector로 바꾸기 위해서 이 알고리즘을 살펴볼 필요가 있습니다. 이제 HOG + Linear SVM을 줄여서 HLS라고 하겠습니다.
HLS는 3개의 키포인트들을 가집니다! 알아봅시다!
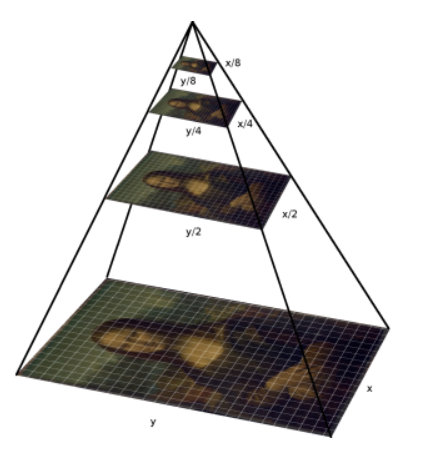
HLS의 키포인트 중 첫번째는 “이미지 피라미드”를 만드는 것입니다.
“이미지 피라미드”란 그림2처럼 이미지를 여러 스케일로 표현한 것입니다.
 |
|---|
| 그림 2 |
가장 아래에 있는게 원본이고 위로 올라갈수록 크기가 2배씩 작아지는걸 볼 수 있는데, 어느 정도까지만 줄여나가고 더이상 진행하지 않는다고 합니다. ※ 이미지의 사이즈를 바꿀 때, GAUSSIAN blurring 같은 기법을 사용하여 이미지를 smooth하게 만들기도 합니다.
HLS의 키포인트 중 두번째는 sliding windows를 이용하는 것입니다.
 |
|---|
| 그림 3 |
이름에서 말하는 것과 같이, 그림 3처럼 이미지를 훑어서 내려오는 걸 생각하면 됩니다. 위 이미지는 빠르게 읽고 내려오는 것 같지만, 한 스텝, 한 스텝마다 아래의 과정을 거칩니다.
- ROI를 추출한다 : 윈도우를 슬라이딩하면서 윈도우 영역을 추출하는 것을 뜻함.
- 추출된 영역을 이미지 분류기 ( ex : linear SVM, CNN 등) 에 적용한다.
- 우리가 원하는 결과(확률 값)를 얻는다.
위 과정을 “이미지 피라미드”에 적용하면, 우리는 입력 이미지의 다양한 스케일에서 object의 위치를 특정할 수 있습니다. 이것이 어떻게 가능할까요? 방법에 대해서는 이 글이 끝나면 아마 알게 될 것입니다!
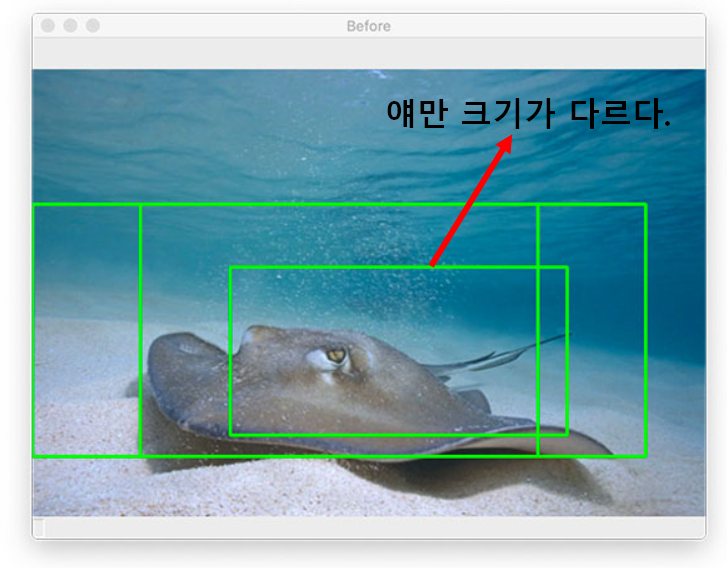
이미지의 크기가 크면 bbox의 크기가 클 것이고, 이미지의 크기가 작으면 bbox의 크기가 작을 것입니다. 그리고 bbox마다의 object에 대한 확률이 나올 것이구요. 이 정보들을 가지고 이야기를 시작합시다.
 |
|---|
| 그림 4 |
그림 4는 크기가 다른 bbox들이 존재합니다. 왜냐하면 image 스케일을 다양하게 한 후, window sliding을 했기 때문이죠.
HLS의 마지막 단계는 non-maxima suppression을 하는 것입니다.
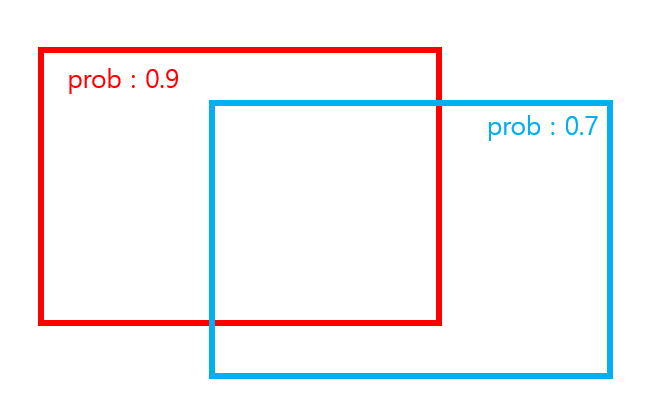
non-maxima suppression이 뭐..죠..? 설명을 위해 알아야 할 개념 IoU에 대해 간단히 설명하겠습니다.
 |
|---|
| 그림 5 |
그림 5처럼 sliding window를 통해 각 영역의 확률이 나타난 bbox들이 있다고 해봅시다.
 |
|---|
| 그림 6 |
 |
|---|
| 그림 7 |
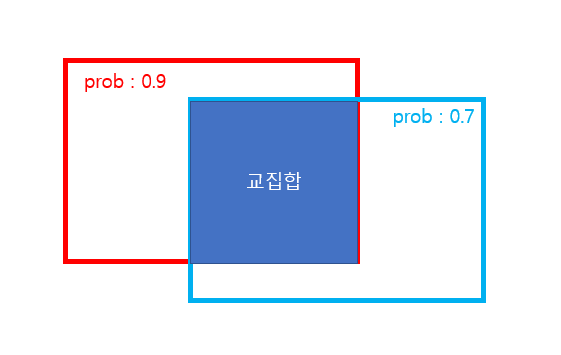
그리고 두 영역의 합집합을 100(그림 6), 교집합을 60(그림 7) 이라고 합시다. 그러면 IoU ( intersection of union) 이라는 것은 두 영역의 교집합 / 합집합 으로 나타낼 수 있는데, 이 값은 60/100 = 0.6이 됩니다.
non-maxima suppression의 방법은 다음과 같습니다.
 |
|---|
| 그림 8 |
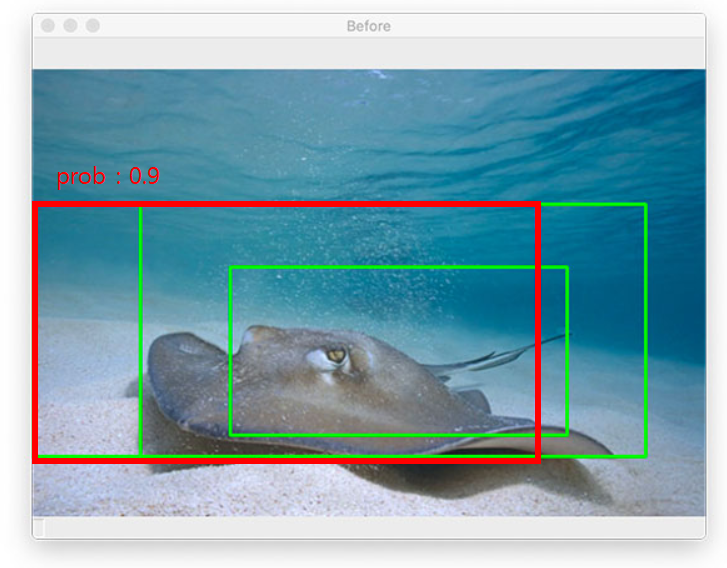
그림 8과 같이 Object를 나타내는 확률이 가장 큰 BBOX를 기준으로 잡습니다. 그리고 같은 object를 나타내는 다른 BBOX들과의 IoU를 각각 다 구합니다. IoU의 threshold를 설정하여 전처리를 합니다 .
- IoU >= threshold 일 경우, 같은 object를 bbox한 것이라고 판단하여 파란색 bbox를 삭제하고 가장 확률이 높은 것만 남긴다.
- IoU < threshold 일 경우, 서로 다른 object를 판단한다고 생각하여 두 bbox를 모두 남긴다.
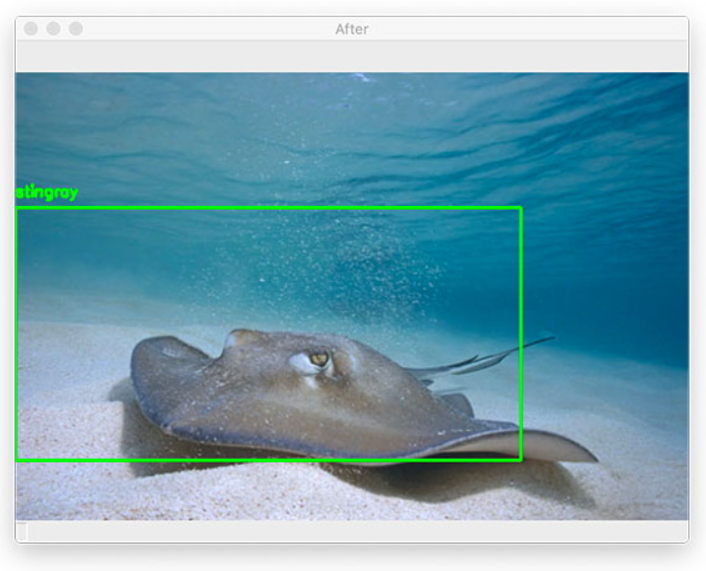
위 방식을 거치면, 가장 확률이 높은 bbox들만 남고 나머지는 사라지게 됩니다.
그리고 bbox는 결국 sliding window의 잔재이고, 이것은 각각 예측 class와 score를 갖고 있으므로 그림 9와 같이 결과를 표현할 수 있게 됩니다.
 |
|---|
| 그림 9 |