
object detection에 대해서 알아보자 - STEP 2
업데이트:
카테고리: object detection, 딥러닝
이전 글에 이어서 계속해서 리뷰를 하겠습니다.
STEP 1에서는 HLS를 이용하여 object detection..? 이라기보단 bbox를 만들고 labeling 및 score를 따지는 방법을 알아봤습니다. 하지만 이것은 traditional computer vision이고, 여러 이미지를 스케일링해서 sliding window를 하고, 각각을 분류기에 넣어서 확인하고.. 하는 작업을 매번 한다는 것은 너무나 비효율적입니다. 따라서 우리는 조금 더 발전된 기술에 대해 알아보려고 합니다.
Region proposals versus sliding windows and image pyramids
우리는 Selective Search algorithm 에 대해 알아보려고 합니다. 줄여서 SS라고 부르겠습니다. 이전에 배운 HLS에서 이미지 스케일 및 윈도우 슬라이딩은 2가지 단점을 갖습니다.
- 치명적일정도로 너무 느리다.
다양하게 스케일된 이미지마다 윈도우를 잡아서 끝까지 슬라이딩을 하니.. 이 얼마나 비효율적일까요?
- 파라미터에 따라 결과가 바뀔 가능성이 높다.
이미지 스케일을 어떻게 할 것이며, 슬라이딩할 윈도우 사이즈는 어떻게 할것인가에 따라 성능이 매우 달라집니다.
이런 단점들 때문에, computer vision 연구자들은 슬라이딩 윈도우 대신 automatic region proposal generators를 제안합니다. Region Proposal Algorthm (RPA)는 이미지를 보고 object를 포함할 거 같은 이미지의 영역을 찾는 것이라고 생각하면 됩니다. RPA는 3가지의 장점을 갖습니다.
- 기존의 HLS의 이미지 피라미드, 슬라이딩 윈도우보다 더 빠르고 효율적이다.
- object를 포함하는 이미지의 영역을 정확하게 찾는다.
- RPA를 통해 얻어진 “후보 영역들”을 분류기에 넣어 영역을 라벨링하면 object detection이 완성된다.
What is Selective Search and how can Selective Search be used for object detection?
이제, SS는 무엇이고 object detection에서 SS를 어떻게 사용하는지 알아봅시다. SS는 2012년에 발표된 연구입니다. SS는 superpixel algorithm을 사용한 이미지를 over segmenting 함으로써 작동합니다. superpixel algorithm에 대해선 아래 페이지들을 참고합시다.
superpixel algorithm을 사용하면, 그림 1과 같은 결과를 얻게 된다고 생각하고 넘어갑시다.
 |
|---|
| 그림 1 |
SS는 그림 1과 같은 결과를 아래의 특성을 이용하여, object를 포함할 수 있는 이미지의 영역을 찾기 위해 superpixel들을 합치려고 합니다.
SS의 중요한 5가지의 특성들은 다음과 같습니다.
- Color similarity
이미지의 각 채널마다 25개의 bin으로 히스토그램을 계산합니다. {25개의 bin이라는건 아마도 0~10, 11~20, 21~30 , … 231~240,241~255 뭐 이런식으로 pixel의 값 구간을 25개로 나눠서 표현하는 것 같네요.} 그러면 이제 비슷비슷한 값의 범위끼리 묶이게 됩니다. 그리고 $25 \times 3=75-d$인 final descriptor를 얻습니다. 어떤 두 영역들의 Color similarity를 측정하려면, histogram intersection distance를 사용하면 된다고 합니다.
histogram intersection 알고리즘을 간단히 이야기하면.. object의 identity가 color에 굉장히 의존적일 때, 이 방법을 쓰면 물체를 분류할 수 있다는 것 같네요.. 더 자세한 내용은 위 링크를 들어가서 봅시다.
- Texture similarity
텍스쳐의 경우, SS는 채널당 (rgb) 8방향으로의 가우시안 미분을 추출합니다. 이 방향들은 채널당 10-bin histogram을 계산하기 위해 사용되고, 마지막 texture descriptor는 8x10x=240-d 가 만들어집니다. 어떤 두영역의 텍스쳐 유사도를 계산하려면 histogram intersection을 다시 사용하면 됩니다.
- Size similiarity
SS가 사용하는 size similarity metric은 작은 영역들이 나중에 그룹화되는 것이 아니라 먼저 그룹화 되는 것을 선호합니다. 많은 유사도들을 통해서 object가 있을 것이라고 생각되는 부분을 골라주는 과정을 SS라고 생각하면 된다고 하네요..
그 외에 4,5는 링크에 들어가서 한번 보시길 바랍니다.
우리는 STEP 1에서 슬라이딩 윈도우를 이용해 굉장히 비효율적으로 region을 설정했습니다. 이 방법을 대신해서 “object가 있을법한 영역”을 추천받는다고 생각해봅시다.
그림 2를 보면 이해가 될 것입니다.
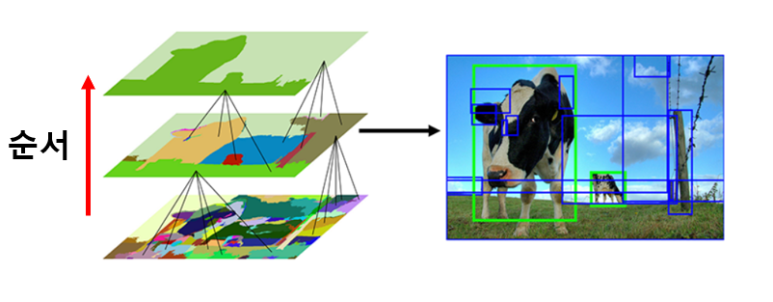 |
|---|
| 그림 2 |
왼쪽에 제일 아래부분에 있는 이미지부터 순서대로 SS를 통해 위로 올라가면서 segment를 하는 것 같네요. 제일 아래에 있는 부분은 superpixel 알고리즘을 사용하여 segment를 한 것이고, 가운데 부분은 SS중 뭐.. 컬러라던지 다양한 유사도를 통해 픽셀들을 뭉쳐가는 과정이라 보면 될 것 같습니다. 이런 방식을 통해 오른쪽과 같이 “object가 있을 법한 영역” 의 후보 지역들을 저렇게 제안할 수 있습니다.
여기서 중요한 점은 비슷한 특성을 지닌 픽셀들끼리 묶어준 것이지 “무엇”을 segmentation 했다는 게 아니라는 것을 압시다. 다시 말해서, 아직 분류기를 거치지 않아서 labelling을 할 수 없다는 뜻입니다.