
논문 공부: R-CNN 계열
업데이트:
카테고리: object detection, 논문 리뷰, 컴퓨터 비전
기초 R-CNN은 이미지를 추론하는데 매우 느린 속도를 보였다. 이를 개선하기 위해 나온 Fast R-CNN부터 핵심만 정리하여 Mask R-CNN에 대해 간단히 설명을 적어보자. 다시 정리하는데 약초님의 블로그를 많이 참고했다.
1. Fast R-CNN
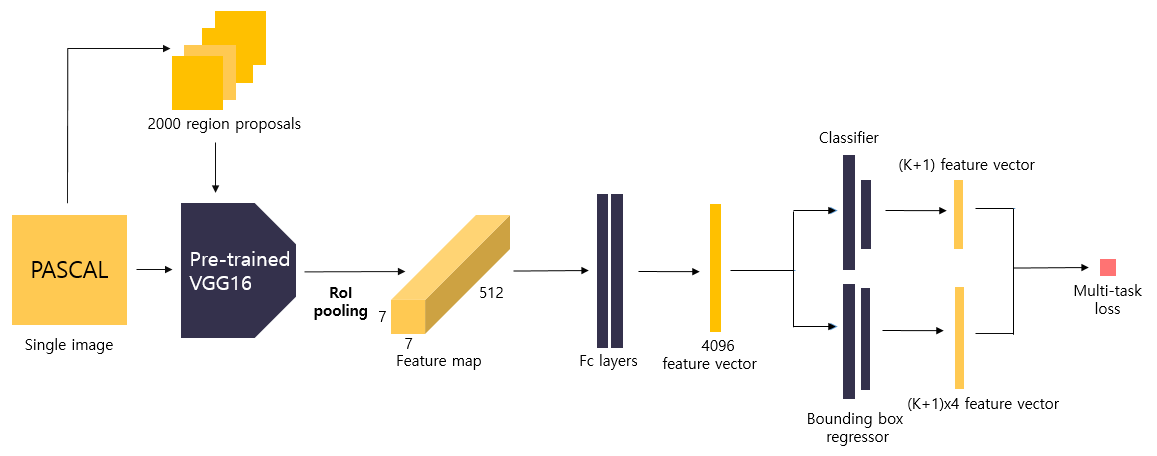 |
|---|
| Fast R-CNN 구조 |
대략적인 흐름도
- 이미지에서 backbone 네트워크를 적용해 feature map을 얻고, selective search도 적용해 2000개의 region proposals을 얻는다.
- region proposals은 이미지로부터 뽑았기 때문에, 크기가 크다. 그러나 feature map은 sub-sampling 과정을 거치면서 작아졌으므로 region proposals의 크기와 중심좌표를 sub-sampling ratio에 맞게 변형시켜준다.
- feature map과 sub-sampling된 region proposals를 사용하여 RoI를 얻게 된다.
- fully connected layer에 전달하기 위해 고정된 feature map을 얻어야하므로, RoI를 sub-window의 크기(전결합층에 넣기 위해 고정된 크기를 얘기함)에 맞게 grid로 나눠준다.
- 각 채널의 grid마다 max pooling을 진행해 일정한 feature map을 만들어준다.
- 이 feature map의 채널이 커서 전결합층에 넘어갈 때 가중치 행렬 W가 너무 커서 연산시 속도를 지연시킨다.
예를 들어, 입력 feature map이 $7 \times 7 \times 512 $이고 4096의 feature vector를 뽑는다고 하면 가중치 행렬 W가 $25088\times 4096$의 크기를 갖는다. 이 문제를 해결하기 위해 W를 Truncated SVD를 시켜서 25088 x t 의 fc-layer와 t x 4096의 fc-layer로 쪼개서 2개의 fc-layer를 생산한다.
이렇게 되면 연산량이 기존에 25088 x 4096 이었던게 t x (25088+4096) = 25088 x t + t x 4096 로 연산량이 확 줄게 된다. 단, 정확도가 아주 약간 떨어지게 됨. - 이렇게 Truncated SVD를 지난 feature vector들은 Classfier와 Bounding Box regressor layer들을 만나 (K+1) class feature vector, (K+1)x4 bbox feature vector로 나오게 된다.
RoI Pooling
RoI Pooling은 backbone 네트워크를 거쳐 나온 feature map과 region proposals 단계에서 추천된 정보를 합쳐서 나온 RoI를 지정한 크기의 grid로 나눈 후 max pooling을 수행한다. 각 channel별로 독립적으로 수행해서 입력과 출력이 같은 채널을 갖게한다. 예를 들면 입력 RoI가 $50\times 50\times 512$ 였으면 출력 RoI는 $7 \times 7 \times 512$ 로 나온다.
Multi-task loss
\(Loss = L_{cls}(p,u) + \lambda[u>=1]L_{loc}(t^u,v)\)
- $L_{cls}$는 cross entropy를 뜻한다.
- $L_{loc}$은 Smooth L1 loss를 뜻한다.
- p는 class feature vector, u는 ground truth class score, $t^u$는 bbox feature vector, $v$는 ground truth bbox location 이다.
Hierarchical Sampling
학습시 feature sharing을 위해 서로 다른 이미지 N개의 이미지에서 총 R개의 RoI를 샘플링 한다고 하면, 각각의 이미지에서 R//N개 씩 샘플링 해서 미니배치 학습을 한다. 이 때, 각각의 이미지에서 나오는 샘플링들은 25% 정도를 ground truth와 IoU가 0.5 이상인 것으로, 75%를 IoU가 0.1~0.5인 negative한 것들로 추출한다. 이를 통해 서로 다른 이미지에서 학습하더라도 feature sharing을 하는 경험을 하게 된다.
end-to-end 네트워크들이 미니배치 방법을 써서 feature들이 공유가 되는 것을 모사한 것 같다.
장점
- Fast R-CNN은 region proposals에 RoI pooling을 적용시켜 항상 고정된 크기의 feature vector를 Fully Connected layer에 전달할 수 있게 했다.
- Multi-task loss를 사용해 모델을 한번에 학습시킴으로써 학습 및 detection의 시간이 크게 감소했다.
2. Faster R-CNN
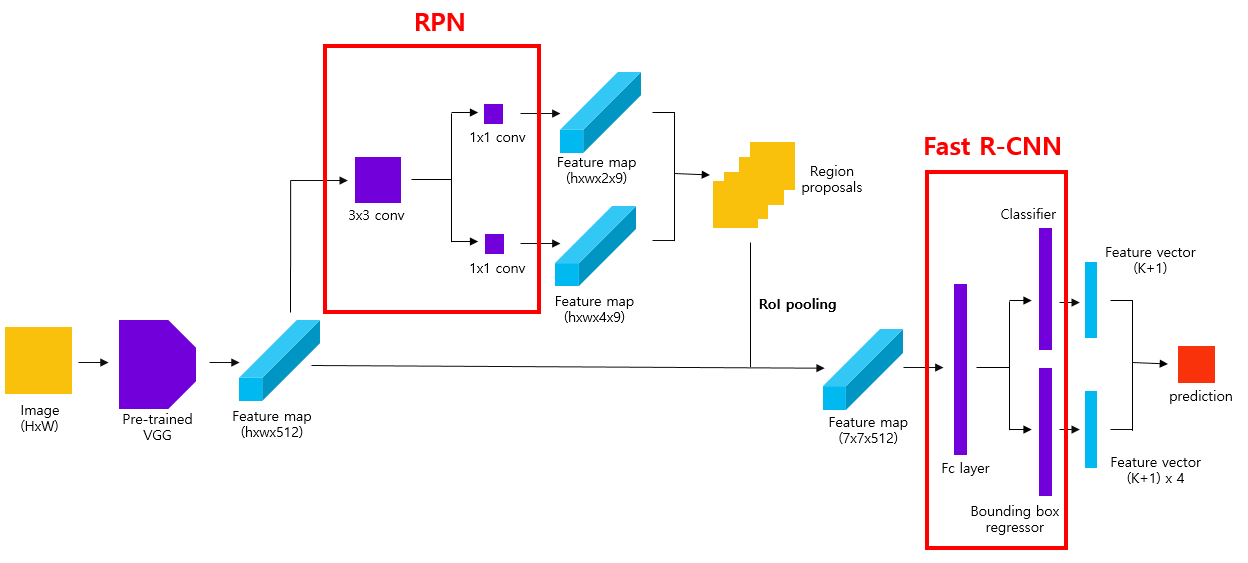 |
|---|
| Faster R-CNN 구조 |
대략적인 흐름도
- 이미지($N\times M\times 3$) 에서 backbone 네트워크를 적용해 sub-sampling된 feature map($a\times b \times 512$)을 얻는다.
- 이미지에서 서로 다른 비유을 가진 anchor를 생성한다. 이 때, anchor의 개수는 ($a\ast b \ast 9$)이다.
- 1.의 feature map에 RPN 네트워크를 적용하여 anchor에 객체가 있는지 여부 판단 feature map ($a\times b\times 2 \times 9$)와 anchor location vector map ($a\times b\times 4 \times 9$)를 추출한다.
- 2,3의 결과들로 영역을 추천할 것이다. 먼저 anchor가 이미지 경계를 넘어가지 않는 것들로 추리고, class feature map의 score로 NMS를 적용해 상위 N개의 anchor만 남긴다.
- N개의 anchor와 ground truth anchor들의 IoU에 따라 positive(>=0.5),negative(0.1<= <0.5)로 라벨링을 한다. feature sharing을 위한 sampling 때문에.
- 1,5의 결과들로 RoI를 생성해 RoI Pooling을 거친다.
- 나머지는 Fast R-CNN의 6,7처럼 진행한다.
- RPN 네트워크 학습을 위해서 2.의 결과들과 ground truth anchor들을 사용해 경계를 넘지 않고 IoU가 0.7이상을 positive, IoU가 0.3 이하는 negative로 라벨링한다.
- 학습은 RPN과 Fast R-CNN을 번갈아가며 학습한다. loss를 같이 쓰는데, RPN은 cls에서 binary CE를 쓰고, Fast R-CNN은 CE를 쓴다.
Multi-task loss(RPN용인듯)
\[Loss = \frac{1}{N_{cls}}\sum_i L_{cls}(p_i,p_i^*) + \lambda\frac{1}{N_{reg}}\sum_i p_i^* L_{reg}(t_i,t_i^*)\]- i : mini-batch 내의 anchor의 index
- $p_i$ : anchor i에 객체가 포함되어 있을 예측 확률
- $p_i^*$ : anchor가 양성일 경우 1, 음성일 경우 0을 나타내는 index parameter
- $t_i$ : 예측 bounding box의 파라미터화된 좌표(coefficient)
- $t_i^*$ : ground truth box의 파라미터화된 좌표
- $L_{cls}$ : Loss loss
- $L_{reg}$ : Smooth L1 loss
- $N_{cls}$ : mini-batch의 크기(논문에서는 256으로 지정)
- $N_{reg}$ : anchor 위치의 수
- $\lambda$ : balancing parameter(default=10)
Detection
최종적으로 얻은 predicted box에 Non maximum suppression을 적용하여 최적의 bounding box만을 결과로 출력한다.
학습 방법
|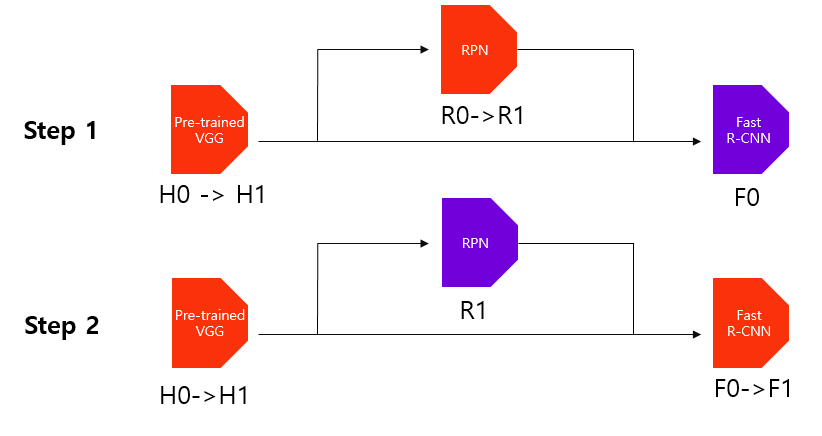 |
|:–:|
|학습 방법|
|
|:–:|
|학습 방법|
- 먼저 Anchor generation layer에서 생성된 anchor box와 원본 이미지의 ground truth box를 사용하여 Anchor target layer에서 RPN을 학습시킬 positive/negative 데이터셋을 구성한다. 이를 활용하여 RPN을 학습시킨다. 이 과정에서 pre-trained된 VGG16 역시 학습된다.
- Anchor generation layer에서 생성한 anchor box와 학습된 RPN에 원본 이미지를 입력하여 얻은 feature maps를 사용하여 proposals layer에서 region proposals를 추출한다. 이를 Proposal target layer에 전달하여 Fast R-CNN 모델을 학습시킬 positive/negative 데이터셋을 구성한다. 이를 활용하여 Fast R-CNN을 학습시킨다. 이 때 pre-trained된 VGG16 역시 학습된다.
- 앞서 학습시킨 RPN과 Fast R-CNN에서 RPN에 해당하는 부분만 학습(fine tune)시킨다. 세부적인 학습 과정은 1)과 같다. 이 과정에서 두 네트워크끼리 공유하는 convolutional layer, 즉 pre-trained된 VGG16은 고정(freeze)한다.
- 학습시킨 RPN(3)번 과정)을 활용하여 추출한 region proposals를 활용하여 Fast R-CNN을 학습(fine tune)시킨다. 이 때 RPN과 pre-trained된 VGG16은 고정(freeze)한다.
쉽게 생각하면 RPN과 Fast R-CNN을 번갈아가며 학습시키면서 공유된 convolutional layer를 사용한다고 보면 됩니다. 하지만 실제 학습 절차가 상당히 복잡하여 이후 두 네트워크를 병합하여 학습시키는 Approximate Joint Training 방법으로 대체된다고 합니다.
장점
- Fast R-CNN이 0.5fps(frame pre second)인 반면 Faster R-CNN 모델은 17fps를 보이며, 이미지 처리 속도 면에서 발전한 결과를 보였다.
- Faster R-CNN은 PASCAL VOC 2012 데이터셋에서 mAP 값이 75.9를 보이면서 Fast R-CNN 모델보다 더 높은 detection 성능을 보였다.
- feature extraction에 사용하는 convolutional layer의 feature를 공유하면서 end-to-end로 학습시키는 것이 가능해졌다.
단점
실시간 detection에는 한계가 있다.
3. Mask R-CNN
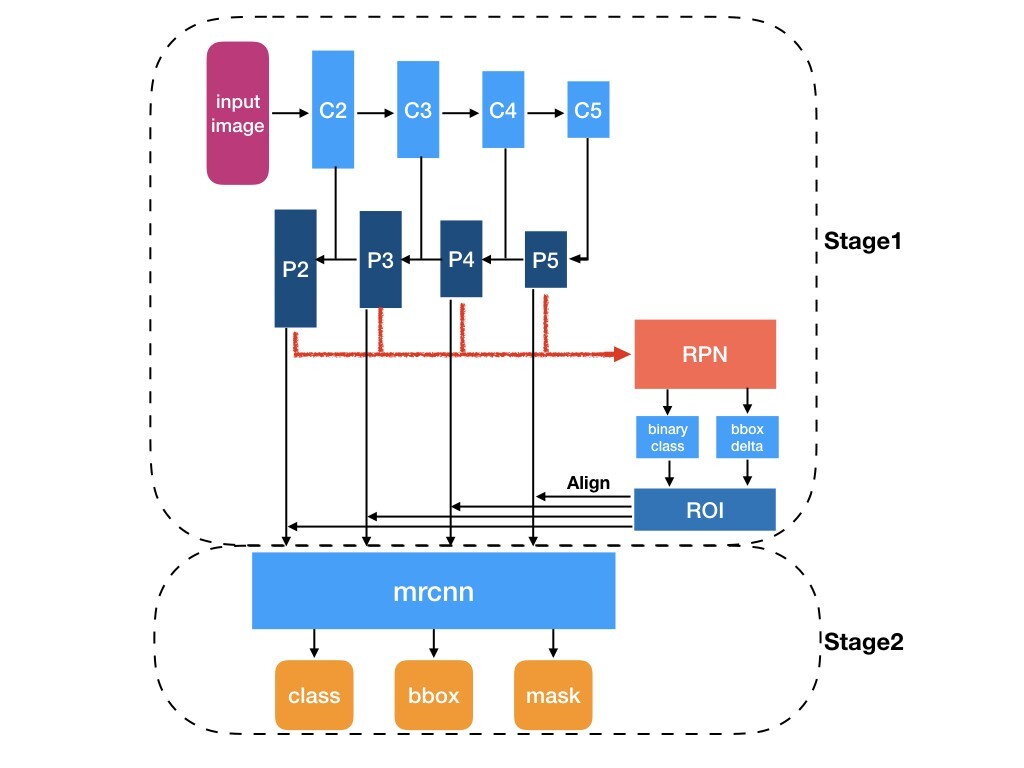 |
|---|
| Mask R-CNN 구조 |
대략적인 흐름도
- 이미지($N\times M\times 3$) 에서 ResNet-FPN backbone 네트워크를 적용해 P2,P3,P4,P5를 얻는다.
1-1. FPN은 입력 이미지에 CNN을 이용해 크기는 절반으로 줄이고, 채널 수를 2개 키운다. 그렇게 해서 깊어질수록 high-level feature들을 추출한다.
1-2. 그렇게 얻은 C2,C3,C4,C5에 1x1 크기의 conv를 사용해 채널을 256으로 만들고, P5는 그대로 추출한다.
1-3. C5는 nearset neighbor 기법으로 upsampling해 C4와 요소별 합을 한 후, aliasing을 줄이기 위해 3x3 conv를 해서 P4를 만든다.
1-4. 이런 식으로 P3,P2 까지 제작한다. P1은 메모리 이슈로 인해 제외한다.
1-5. FPN의 장점은 high-level feature와 low-level feature을 합치면서 각각의 장점인 classfication 과 localization의 feature를 합치는 것이다. - RPN 방식은 Faster R-CNN과 동일하다.
- Mask를 만드는데 있어서 RoI pooling는 quantization과정에서 정보를 손실하여 문제가 된다. 따라서 RoI aligned를 사용한다.
RoI alinged란, 원하는 크기의 sub-window로 RoI를 grid화 한다. 그리고 내부를 가로3,세로3등분을 해서 4개의 점을 찾고, 각각의 점은 주변의 픽셀 값들로 bilinear interpolation을 진행한다. 그렇게 나온 4개의 값으로 max-pooling을 진행하여 sub-window에 넣는다. - classfication과 regressor는 Fast R-CNN과 같고, 마스크 만드는 단계가 추가된다. 마스크는 어려운 것 없다. cnn을 적용해 mask feature map을 만들고 rescale해서 마스크를 제작한다. mask의 각 셀에 sigmoid를 적용해 값을 0~1로 만들고 rescale한 후, mask threshold(=0.5)에 따라 mask segment의 각 픽셀값이 0.5 이상인 경우 class에 해당하는 객체가 있어 1을 할당하고, threshold 미만의 경우 0을 할당한다.
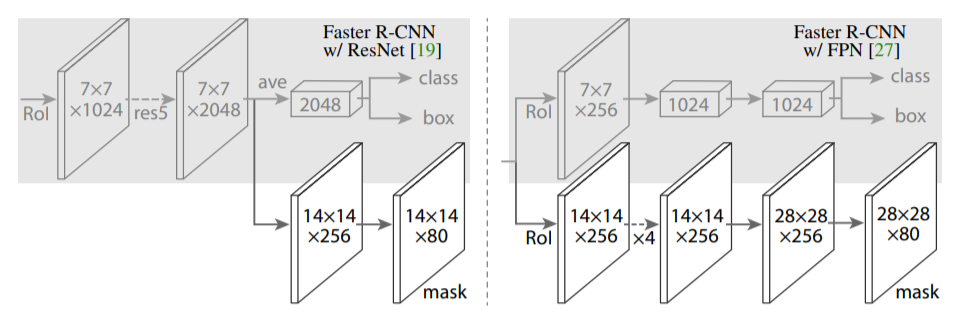 |
|---|
| FPN을 사용했을 때 Mask net 구조 |
Multi-task loss(RPN용인듯)
\[Loss = L_{cls} + L_{box} + L_{mask}\]- $L_{cls}$와 $L_{box}$는 Faster R-CNN과 같다.
- $L_{mask}$는 rescale된 마스크와 정답간의 binary cross entropy loss이다
학습 및 추론
학습시엔 Faster R-CNN의 4-step alternating training을 그대로 사용한다…~
추론시엔 Inference 시에 Proposal layer 구간에서 모든 feature pyramid level에 걸쳐 상위 1000개의 RoI만을 선정한다. 이후 RoI를 classification branch와 bbox regression branch에 입력하여 나온 예측 결과에 Non maximum suppression을 적용하고, 상위 100개의 box만을 선정하여 mask branch에 입력한다. 이러한 방식은 3개의 branch가 평행하게 위치했던 학습 과정과 다르지만, inference 시간을 줄여주고 정확도가 더 높게 나온다는 장점이 있다고 한다.
장점
Mask R-CNN은 ResNeXt-101-FPN을 backbone network로 사용하여 COCO 데이터셋을 학습에 사용한 결과, AP값이 37.1%를 보였다. 이는 당시 instance segmentation task에서 가장 좋은 성능을 보인 FCIS+++와 OHEM을 결합한 모델보다 AP값이 2.5% 더 높게 나온 결과이다. 참고로 detection task에서도 당시 가장 높은 성능을 보였다고 한다.